

i-Scream edu AI 드림마블
아이스크림에듀의 AI는 학습에 대한 문제의식과 그것을 해결하고자 하는 의지로부터 시작합니다.
"아이들은 모두 다 다른 역량과 자기만의 스타일을 가지고 있는데, 왜 획일화된 학습을 해야 할까요?"
"세상에 재미있는 것들이 이리도 많은데, 왜 우리 아이들에게 공부는 늘 재미 없는 것이어야 할까요?"
"왜, 우리 아이들은 공부하라는 잔소리에서 벗어날 수 없을까요?"
아이스크림에듀의 AI기술, 드림마블은 이런 문제들을 해결하고, 아이들과 교사들의 꿈을 키울 수 있게 합니다.
섬세한 진단과 맞춤 학습 추천을 통해 개인화 학습을 실현하고, 상호작용, 경험을 통한 학습으로 몰입할 수 있습니다.
이런 몰입은 자연스레 스스로 학습을 꾸려나가는 자기주도학습 능력으로 이어집니다.
뿐만 아니라 아이들의 길잡이가 되어 줄 교사, 학부모에게 아이들에게 더욱 집중할 수 있는 환경과 전문성을 제공해 줍니다.
일 1,600만 건 이상의 학습 데이터 분석을 기반으로 1:1 개인별 맞춤 학습을 제공하며 쌓아온 아이스크림에듀의
AI 노하우는 교육 분야의 크고 작은 문제를 해결하고 교육의 본질적 가치를 향상 시킬 것입니다.
개인화 맞춤 학습 설계
- 아이스크림에듀는 AI분석기반으로 학습 성장(+)과 부진(-) 신호를 캐치하여 선제적으로 학습자에 필요한 학습 처방 제공하여 홈런 학습자들의 자기주도 학습능력 생성을 위한 학습의 선순환적 고리 체계 형성

AI서비스 기반 기술
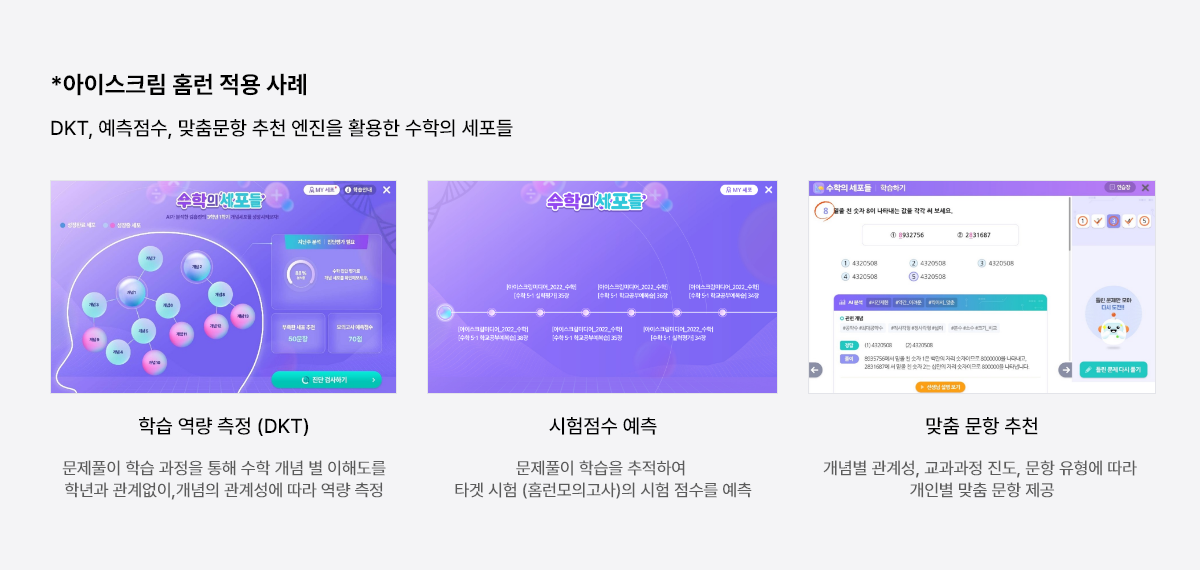
수학 지식맵
- 지식맵은 학습자가 학습하는 내용을 구조화하고 시각화하여 학습하고 있는 내용을 더욱 명확하게 이해하고, 필요한 정보를 쉽게 찾아볼 수 있도록 구성되어 있음
아이스크림에듀의 지식맵은 딥러닝 기반의 지식맵 시뮬레이션 모델로 전문가와 함께 개발되어 적합성이 높으며, 개념 간의 연계성을 파악하여 보다 정확한 진단과 추천을 가능 할 수 있도록 설계 되어 있음 - 또한 모델 변경 및 수정이 용이하고 확장성이 높게 설계되어 있음
학습자의 학습 이력과 과목의 메타 정보를 이용하여 여러 지식 간 선/후행 관계를 표현하여 학습 효율성을 높이는데 큰 도움 제공
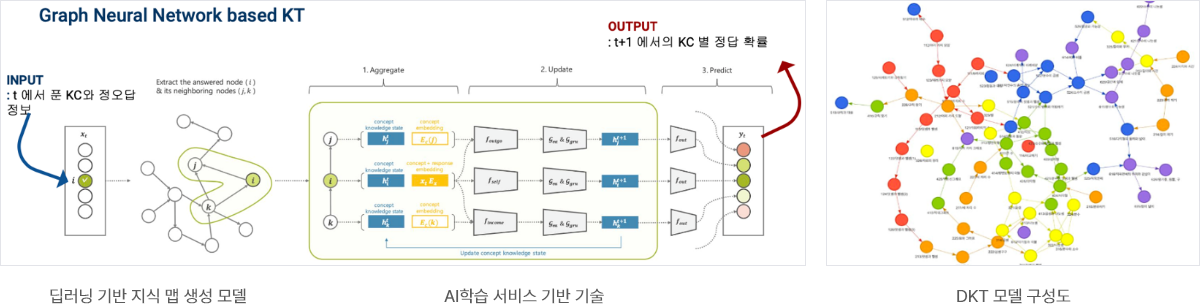
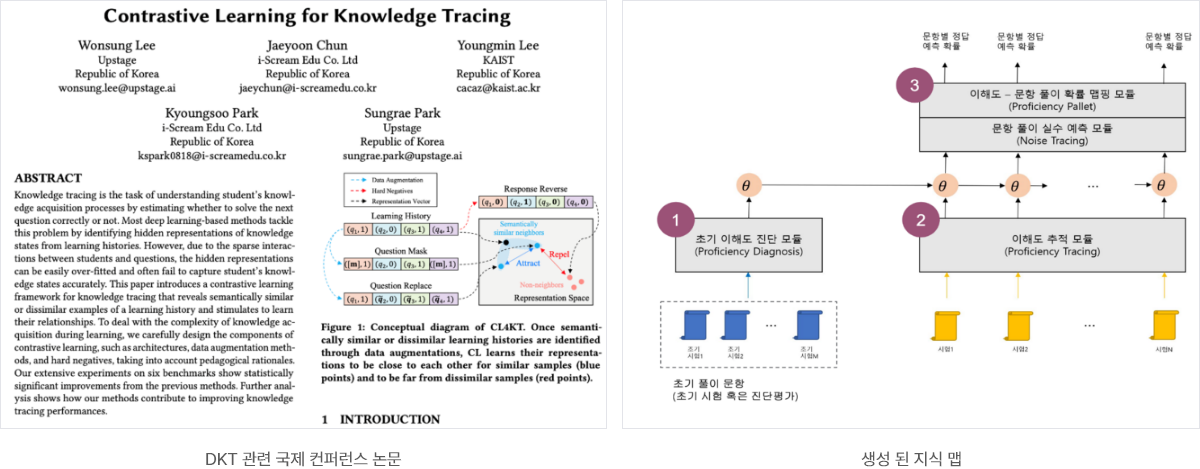
DKT (Deep Knowledge Tracing): 지식추적
- 아이스크림에듀는 2017년 발표 이후 최고의 성능을 보여주는 Transformer 기반이며 딥러닝 모델을 기반으로 기술 자립도 높음
- 학습자의 개인화된 학습 추적 및 진단을 가능하게 하는 Transformer 기반 딥러닝 기반 학습 분석 기술
- 학습자가 문제를 푸는 문항풀이 확률, 풀이실수예측 등을 분석하여 학습자의 이해도를 도출하고 학습 과정을 추적하여 이를 통해 개인화된 학습 계획 및 개선 방안을 제시할 수 있음
- 모델은 데이터와 지식맵, 진단 모델을 가지고 있어서 변경/갱신/도메인 변경 등 확장성이 높으며 최신 아키텍처와 함께 설명력과 성능을 높이기 위해 기존에 공개되지 않은 기술들을 접목하고 있음
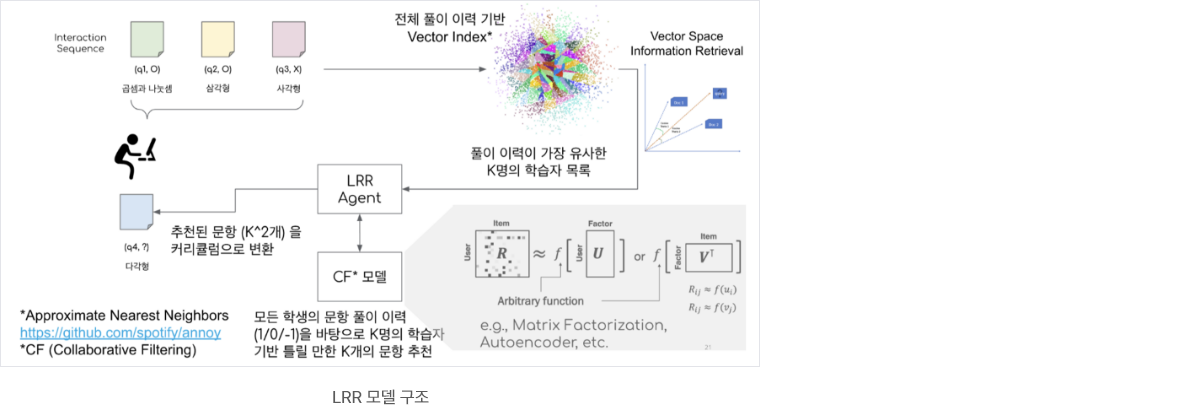
문항 및 컨텐츠 추천 엔진
- 아이스크림에듀는 학습자의 이해도, 문제의 난이도, 풀이 패턴 등을 조합해 기계 학습 및 딥러닝 방식으로 문항을 학습자 중심으로 동적 추천방식으로 제공
- 문항 추천 엔진은 학생들이 푼 문제를 분석해서 그들의 수준과 풀이 패턴 등을 파악하여 가장 알맞은 문제를 추천해 줌
- ANN, CF 등의 기계학습/딥러닝 모델을 조합해서 학생들에게 더욱 정확하고 개인화된 문제를 추천해 줄 수 있음
또한, 문항 추천 엔진은 이러한 추천 과정에서 데이터를 자동으로 수집하고 분석하기 때문에, 보다 높은 자립도와 효율성을 가지고 있음
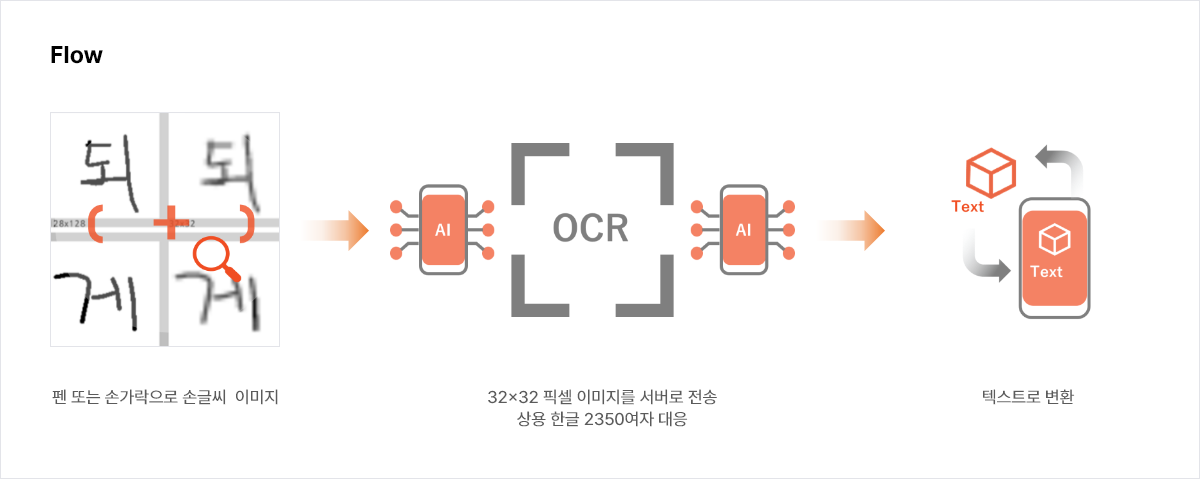
OCR(Optical Character Recognition) : 광학문자판독기술
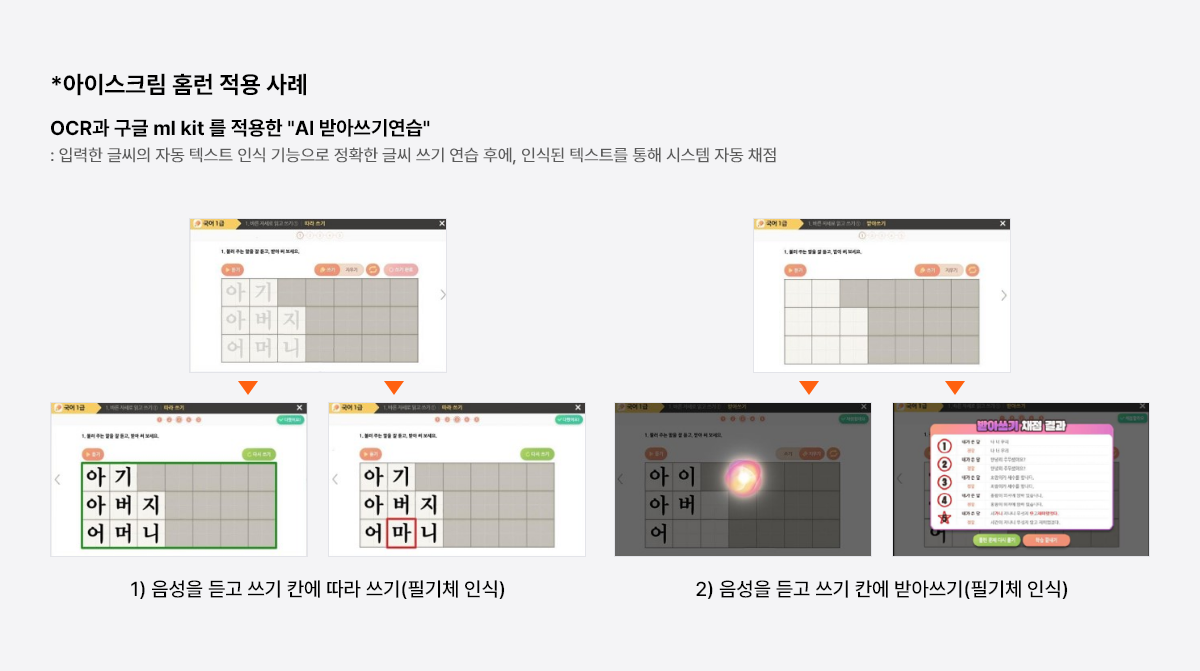
- 손 글씨를 이미지로 텍스트로 전환하는 기술
- 70만개 손 글씨 데이터 기반으로 홈런만에 자체 학습 모델 개발 및 하이브리드 엔진 전략으로 타사 대비 인식률 높음
- 획순에 관계 없이 이미지로만 결과 전송 되므로 다양한 플랫폼에 대응해서 사용 할 수 있음
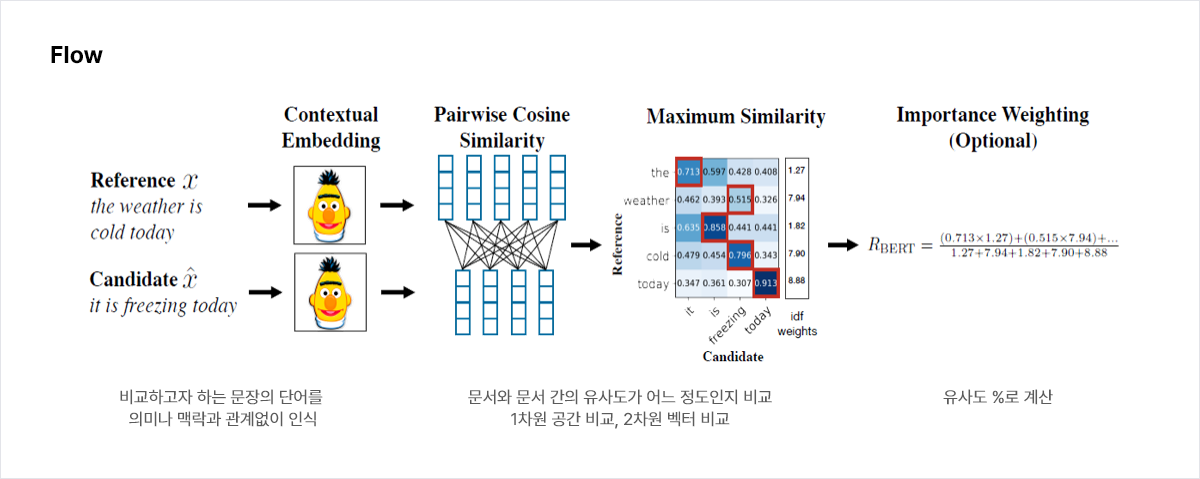
BERT (AI기반 문장 유사도 평가 기술)
- 실제 사람이 인지하는 의미상의 기준으로 두 문장 간의 유사도를 %로 계산해서 문장 유사도 (Semantic Textual Similarity) 측정하는 기술
- 두 문장 간의 유사도를 %로 계산하여 실제 사람이 인지하는 의미상의 기준으로 판독
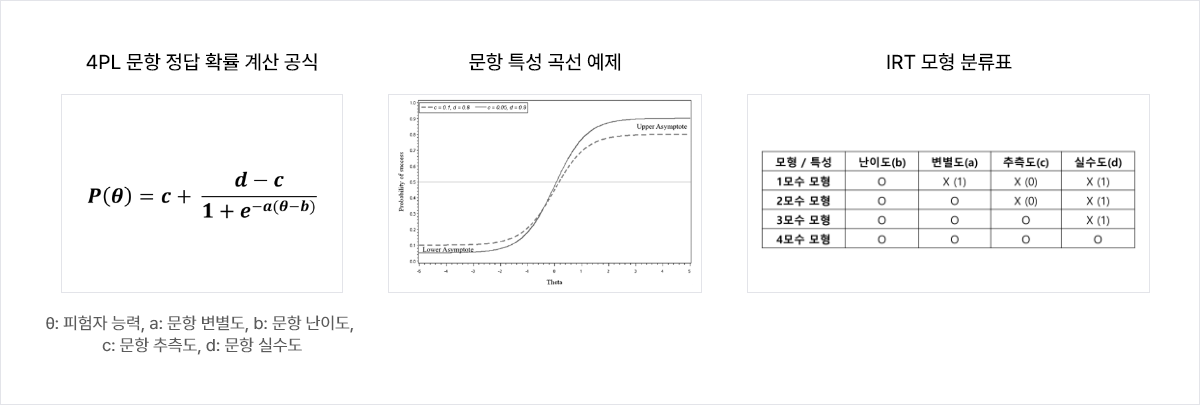
IRT (Item Response Theory) : 문항반응이론
- 문항반응이론(Item Response Theory)은 피험자들의 문항 풀이 결과를 분석하여 피험자의 능력 수준과 문항의 특성(난이도, 변별도 등)을 추론
- 문항의 특성 수에 따라 1PL(난이도), 2PL(난이도, 변별도), 3PL(난이도, 변별도, 추측도), 4PL(난이도, 변별도, 추측도, 실수도) 모형으로 구분
- 적용: 4PL 모형을 채택하여 온라인 플랫폼에 적합하게 IRT 추론 네트워크를 구성하여 측정된 데이터를 서비스에 활용
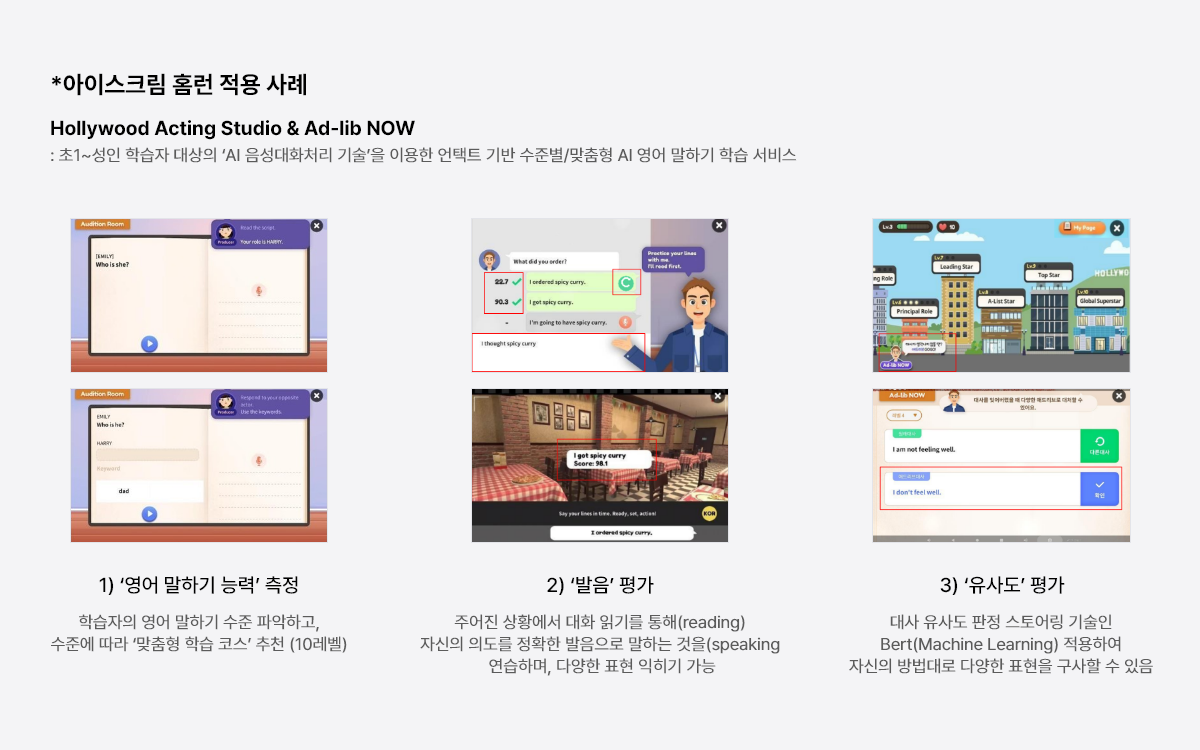
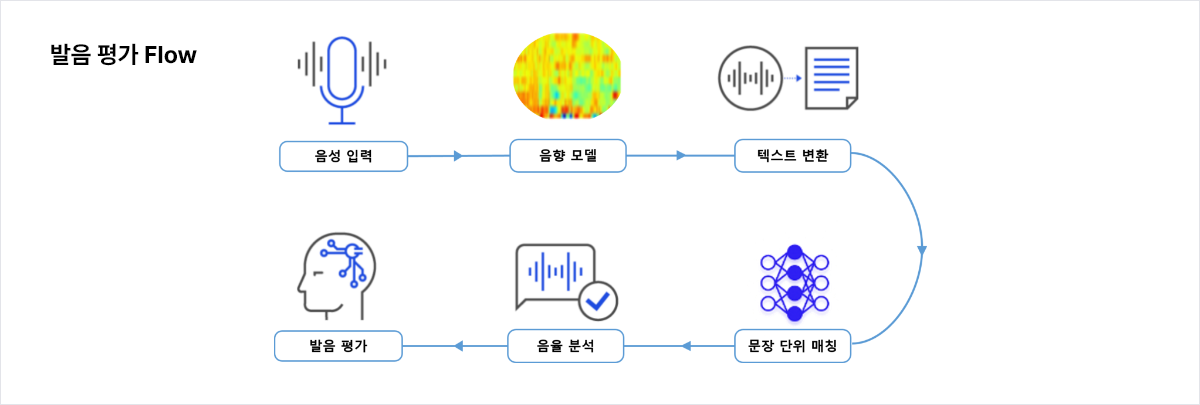
영어 STT와 발음평가
- Speech-to-text 기술은 음성 인식 기술로 컴퓨터가 말한 언어를 텍스트로 변환할 수 있도록 하는 인공 지능입니다.
- 통계 모델, 알고리즘 및 머신 러닝 기술을 사용하여 인간의 말소리에서 생성된 음향 신호를 처리하고 이를 텍스트로 변환합니다.
- 발음 평가 기술은 Language Identification과 STT 기술을 결합하여, 성별, 말하는 방식 및 연령이 다른 익명의 화자의 오디오에서 언어를 감지하고, 대상 문장의 정확도와 말하는 타이밍 등을 고려하여 평가하는 기술입니다.
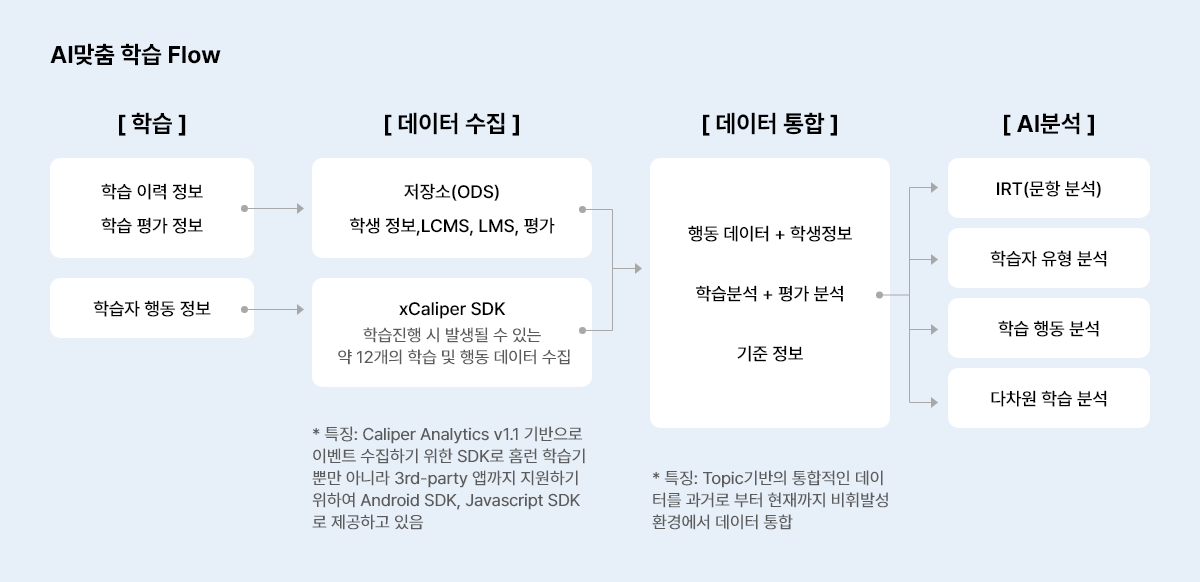
AI맞춤 학습분석체계
- 국제표준인증기반 1EDUTECH의 Caliper Analytics 기준으로 학습 및 학습자 활동 데이터를 체계적인 방법으로 수집
- 학생의 다양한 학습 data를 직접 접근하여 대화식분석기반으로 자기주도 학습의 선순환 구조 생성

인공지능 자연어 처리(NLP) – 대규모 언어 모델(LLM) : 텍스트 생성 및 대화
- 대규모 데이터셋을 기반으로 학습한 인공지능 언어 모델을 사용하여 텍스트 생성 및 대화를 수행
- 주어진 텍스트의 뒤에 이어질 것으로 적절한 텍스트를 예측하는 방식의 자기회귀 언어 모델(Autoregressive LM)을 개발
- 생성형 인공지능을 활용하여 챗봇, 질의응답, 창작 등의 다양한 자연어 처리 문제를 해결
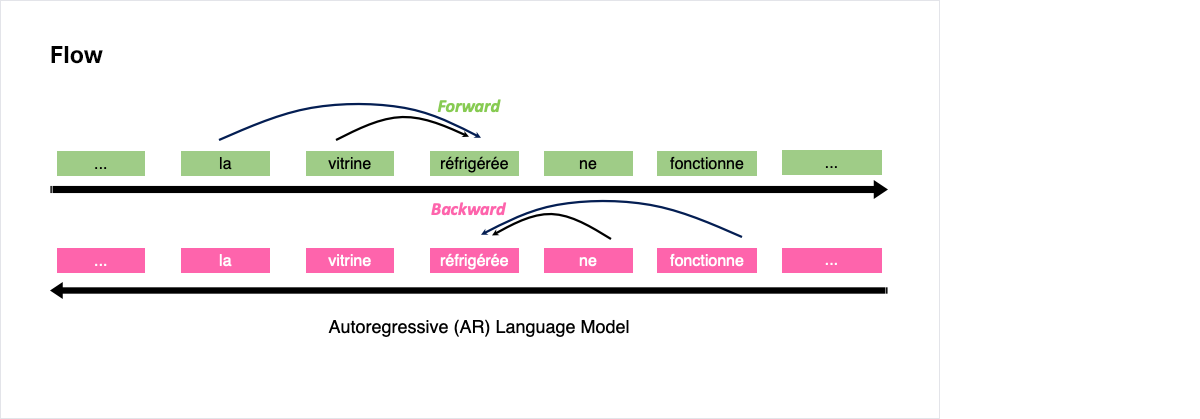
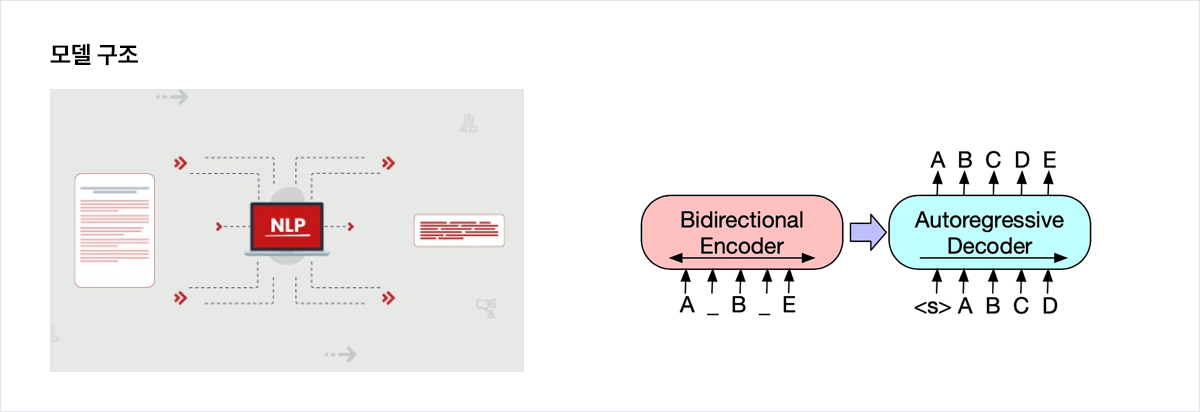
생성 언어 모델
- 생성 언어 모델을 활용하여 문서의 제목과 키워드를 자동으로 추출해낼 수 있음
- 제목 생성 모델: 대규모 문서와 제목 간의 관계를 언어모델이 찾아낼 수 있도록 훈련하여, 스스로 문서에서 제목을 찾아내는 작업을 수행
- 키워드 생성 모델: 대규모 문서에서 가장 핵심이 되는 단어를 언어모델이 찾아내는 작업 수행
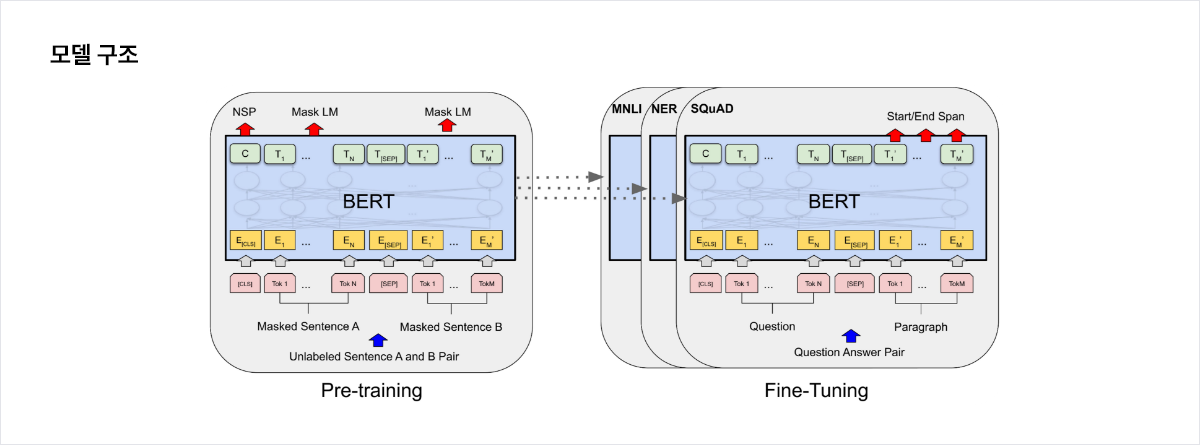
유해성 판단 모델
- 자연어 처리 기술과 머신 러닝 알고리즘을 활용하여 문맥과 단어 등을 파악하여 문장 내에서 유해한 단어를 식별하는 모델
- 단순히 단어의 일치 여부만을 고려하는 것이 아니라, 문맥을 이해하여 이를 통해 보다 정확하고 효과적인 유해성 단어를 감지할 수 있는 장점이 높음

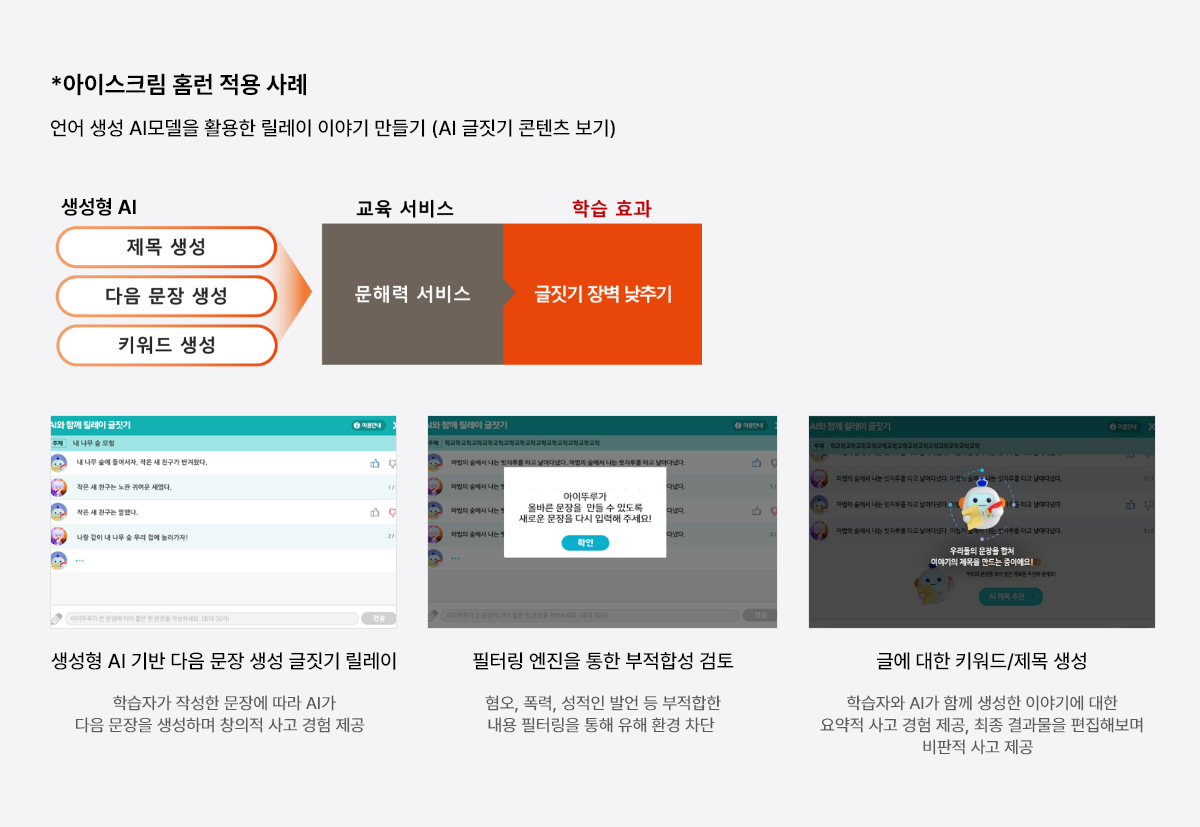
AI 보유기술 조견표
